OS Xの「辞書」アプリで「英辞郎」を使う
11月 6th, 2007先の記事でも書いたように、Mac OS X v10.5 “Leopard”の「辞書」アプリケーション(辞書.app / Dictionary.app)用の辞書はユーザーが追加できるようになっている。そこで、定番の英和辞書「英辞郎」を変換するツールを作ってみた。英辞郎は、現時点で最新のv108を使用している。
使い方は以下の通り。
・OS Xのインストールディスクに含まれる開発ツールをインストールする(「Optional Installs」→「Xcode Tools」→「XcodeTools.mpkg」を実行)
・「/Developer/Exmaples/Dictionary Development Kit/project_templates」フォルダ(OS X 10.7以降は「/Developer/Extras/Dictionary Development Kit/project_templates」フォルダ)を適当な場所にコピーする
→(※OS X 10.7 Lion以降用のXcodeはMac App Storeから入手する。注意点については、下の2012年6月12日/30日の追記を参照のこと)
・コピーした「project_templates」フォルダに、英辞郎の英和辞書データ「EIJI-???.TXT」、略語郎「RYAKU???.TXT」をコピー(英辞郎と略語郎は1つの辞書にした方が使い勝手がよいのでこうしている)。???は英辞郎のバージョンによって異なる
・ここから「eiji_conv???.zip」をダウンロードして解凍し、同じく「project_templates」フォルダにコピーする(同じファイル名は「上書き」)
・「ユーティリティ」フォルダの「ターミナル」アプリケーション(Terminal.app)を起動して、「cd」コマンドで(コピーした)「project_templates」フォルダに移動する
・ターミナルで、「ruby -Ks ryaku_conv.rb < RYAKU???.TXT > Ryaku.txt」と入力(略語郎内のリンクを英辞郎の表記に合わせている)
・「ruby -Ks cat.rb EIJI-???.TXT Ryaku.txt > Eijiro.txt」と入力(英辞郎と略語郎のファイルを連結して「Eijiro.txt」というファイルを生成)
・「ruby eiji_conv.rb < Eijiro.txt > MyDictionary.xml」と入力(2GBのメモリを搭載したMacBook(2GHz)で約20分)
・「make」と入力(同環境で約40分)→(Snow Leopardの辞書ツールでは、生成される辞書のサイズが小さくなる代わりに作成時間が大幅に伸びた。十数〜数十時間を要することがある)
・「make install」と入力
※「ruby eiji_conv.rb < Eijiro.txt > MyDictionary.xml ; make ; make install」と入力すれば、3つの作業をまとめて実行できる
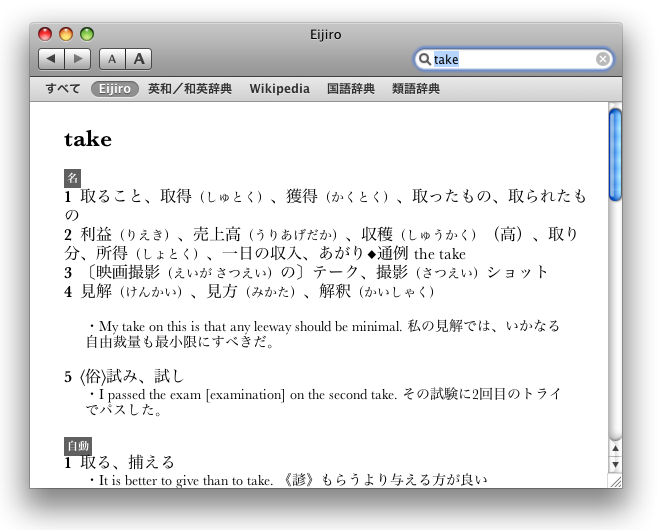
・「辞書」アプリケーションを立ち上げると、英辞郎(Eijiro)が使えるようになっている。なっていない時は、「環境設定…」で英辞郎にチェックを入れる
control+command+Dを押しっぱなしにしていると、マウスカーソル近くの単語を自動認識して辞書を引いてくれるのでとても快適だ。
 出来上がったデータはけっこう大きくなる(略語郎こみで1.36GB)。
出来上がったデータはけっこう大きくなる(略語郎こみで1.36GB)。
アップルが提供するツールでは、他の項目とリンクしうる本文内の箇所について自動的にインデックスを作成する模様。このインデックスがかなり大きくなっているようだ。リンクさせたい箇所を明示的に指定すれば、インデックスは小さくなるだろう。ただ、自動的に作ってくれるインデックスの方が使い勝手がよいのではないかと思う。
(2007年11月9日追記)
いくつかバグ取りと改良を行った。
○v0.01→v0.02の変更点
・品詞が間違って付けられることがあったのを修正
・<→単語>という形式で飛び先が明示されているものにはリンクを張った
・URLをクリックすると、該当ページにジャンプするようにした
※URLの判別ルーチンは、『Ruby Magic―Rubyで極める正規表現』を参考にしている。
(2007年11月12日追記)
 ○v0.02→v0.03の変更点
○v0.02→v0.03の変更点
・空行処理
○v0.03→v0.04の変更点
・スタイルの指定(品詞、定義の順、ルビ、文例)
表示が見づらかったので、スタイルシートで体裁を整える。一部行間隔がおかしいところもあるが(スタイルシートって難しい……)、けっこう見やすくなった。
スタイルシートを変えたい場合は、「~/Library/Dictionaries/Eijiro.dictionary/Contents/DefaultStyle.css」を修正すればOK。スタイルシートの修正だけならば、辞書データを再作成する必要はなく、辞書アプリを再起動するだけでいい。
(2007年11月12日追記(続き))
○v0.04→v0.05の変更点
・品詞名のついていない項目で、スタイル指定が間違っているのを修正
静的なデータを加工するだけなのに、けっこうバグが出る……。これで問題はなくなったと思いたい。
(2007年11月15日追記)
○v0.05→0.06の変更点
・名詞の複数形や動詞の過去形など、変化形でも引けるように改良。
※ただし、熟語になっているものは変化形では引けない。
(2007年11月20日追記)
日本郵便の郵便番号データの変換ツールを公開。詳しくはこちら。
(2007年11月27日追記)
○v0.06→0.07の変更点
・2通りの変化形に対応。例えば、「evil」の比較級は「eviler」と「eviller」があるが、どちらでも引けるようにした。
・リンク先が2つ以上ある場合にも、きちんとジャンプできるようにした。
・辞書名を「Eijiro」から「英辞郎」に変更。
(2008年2月12日追記)
EPWINGの辞書を使えるようにしてみた。詳しくはこちら。
(2009年8月31日追記)
Snow Leopard付属ツールで辞書データを作成すると、Leopard上で作った場合に比べてサイズが2/3になる。ただし、作成時間も延びているので注意。英辞郎+略語郎のデータを初代MacBookでmakeするのに、22時間を要した。
(2010年5月14日追記)
○v0.07→0.08の変更点
見出しが長すぎる項目があるとエラーが出てしまうことがあった。そこで、見出しが長すぎる(512文字以上)項目はスキップするようにした。
(2011年4月11日追記)
○v0.08→0.09の変更点
・スタイルシートを一部修正(例文前後の空行など)。
・解説文中の読みがなの表示/非表示が選択可能に。これを行うためには、eiji_conv009.zipの「extras」内にある「MyDictionary_prefs.html」と「MyDictionary.xsl」を、(コピー済みの)「project_templates」フォルダ→「OtherResources」フォルダにコピーしてから、辞書の変換作業を実行する。変換作業終了後、辞書.appを立ち上げ、「環境設定」から英辞郎を選択して「読みがな」の設定を行う(読みがなの設定を行わないと、解説文が正常に表示されないことがある)。
※スタイルシート修正および読みがな設定は、滝本さんからの情報を元にしています。どうもありがとうございました。
(2012年6月12日追記)
Lion用のXcode 4.3にはDictionary Development Kitが含まれていません。
これを入手するためには、まずMac App StoreからXcode 4.3をダウンロード&インストール。Xcode 4.3のアプリケーションメニュー「Open Developer Tool」→「More Developer Tools…」で開発者用のウェブページを開くと、Auxiliary tools for Xcodeをダウンロードすることができ、この中にDictionary Development Kitが入っています。
なお、Auxiliary tools for Xcodeのダウンロードには、Appleの開発者用アカウントを作成する必要があるので注意(無料で作成できます)。
(2012年6月30日追記)
2012年6月12日に追記した内容の補足。
Xcode 4.3以降用のDictionary Development Kitを使う場合、一部修正が必要になります(Hiroさんより情報をいただきました)。
>本サイトからダウンロードできる,「eiji_conv009.zip」に含まれる「Makefile」をテキストエディットで開き,
>DICT_BUILD_TOOL_DIR = “/Developer/Extras/Dictionary Development Kit”
>の記述を,Dictionary Development Kitをインストール(コピー)したディレクトリに書き換えることで,makeコマンドが起動します.
>例えば,Dictionary Development Kitを「アプリケーション」フォルダにインストールした場合,
>DICT_BUILD_TOOL_DIR = “/Applications/Dictionary Development Kit”
>に書き換えます.
9月 11th, 2012 at 13:26
ちょっと検証している余裕がないのですが、下記サイトが参考になるかもしれません。
http://d.hatena.ne.jp/Nos/20120812/1344788577
上記サイトでは、EDP版ではなく書籍版第5版を使用している点が異なります。サイトで説明されているeiji_convの書き換えは、EDP版のデータを使うなら不要ですが、それ以外の手順は同じはずです。
10月 7th, 2012 at 06:31
このサイトを見て無事MACの辞書アプリに英辞郎をインストールすることができました。 パソコンにはずぶの素人といってもいいくらいです。 記載していただけたら有り難いポイントがいくつかあります。 これがあれば僕のような素人さんも、もっとスムーズに行くと思います。 Mountain Lionで上手く行きました。 ーーーーー (1)Xcodeですが、これだけではDictionary Development Kitが入っておらず、 preference/ download /common line toolsをダウンロードするとその中に入っていました。 (2)ターミナルがすごく苦手だったのですが、パス(ファイルの場所)を記述するのに、 すごく苦労しました。合ってると思っても違ったり。 マックはファイルのアイコンを、ターミナルにドラッグドロップするだけで、 自動的にパスを記述してくれます。これはすごく便利です。 これに気づくまでに数時間かかりました。 (3)英辞郎のデータがどのように販売されているか知らなかったのですが、 先日購入した最新バージョンは、英辞郎として販売されていて、その中に英辞郎や略辞郎などのデータがファイル別に全部入っていました。ファイル名でしか違いは分かりませんでしたが。 昔は別々だったのでしょうか。分かりにくいところではあります。 本当に便利になりました。 僕は古いMacBookエアーだったので、計算に24時間くらいかかりました。 どうも有り難うございました。
11月 9th, 2012 at 18:20
お陰様で辞書に英辞郎を組み込むことに成功いたしました。ありがとうございます。ただ、一つ気になる事として、辞書検索結果の吹き出しの中で、英辞郎の見出しのフォントが太文字で大きい為、見出しの単語しか表示されません。クリックすればその単語の意味も確認できるのですが、他の辞書の様なサイズに変換し、最初の意味程度が吹き出しの一発目から表示できたらいいなと思っています。 スタイルシートなど変更して英辞郎の表示スタイルを変えることはできるのでしょうか?もし、方法がお分かりでしたら簡単にでも結構ですのでご教示願えないでしょうか。 以後後人の参考になるよう自分の導入環境 Mac mini(late2012), 2.5GhzCi5, 8GB OSX 10.8.2 Xcode 4.5.2 (Dictionary Development Kit, Command Line Tools別途ダウンロード) “make”実行に12時間程度かかりました。
12月 27th, 2012 at 09:40
Akihiroさん
同様の現象が発生しましたが、解消することができました。
たぶん、ApplicationsフォルダにDictionary Development Kitフォルダをコピーし、makefileにはホームページの記述をそのまま貼り付けたのではないでしょうか。(私は初心者なので、安全策を採ろうとしたのでした。)
その場合、「”/Applications/Dictionary Development Kit”」両端の「”」が災いします。これを書き換えるとmakeを実行することができました。
4月 15th, 2013 at 18:04
hiro さんへ: インストール済みの 英辞郎.dictionary 内の DefaultStyle.css に
html.apple_client-panel h1 { display: none; }
を追加すれば、ポップアップには見出語し自体が表示されなくなります。 html.apple_client-panel
を用いれば、ポップアップ固有のカスタマイズが いろいろ可能です。
11月 17th, 2013 at 17:49
[…] あとはこのへん。 OS Xの「辞書」アプリで「英辞郎」を使う Leopardの「辞書」アプリで郵便番号辞書を使う Leopardの「辞書」アプリでEPWING辞書を使う Leopardの「辞書」アプリで「ランダム […]
12月 10th, 2013 at 18:33
[…] さて、このアプリがすごい No.003 Dictionary.appender ? reliphoneから教えていただいたのですが、iOSの内蔵辞書は自分で自由に追加できるとのこと! やり方は簡単で、Dictionary.appenderというアプリをiPhone/iPadにインストールして、辞書を指定するだけ。 Dictionary.appenderが対応しているのは、Mac(OS X)の標準辞書アプリで使われている辞書形式です。私もこれまで、郵便番号とか英辞郎をOS Xの辞書アプリで使えるようにしてきたので、これがもしiOSで使えるならすばらしいに違いない??。 […]
1月 24th, 2014 at 15:58
以前こちらの方法で辞書.appに英辞郎を入れて使用していたのですが、英辞郎のバージョンもかなり進んで語数も増えたので辞書ファイルを作り直して入れようとしたのですが、手順通りやっても辞書ファイルを変換することができませんでした。
現在OSはMavericksですがどうもRubyのバージョンが上がって仕様がかわってしまったみたいです。
icodeがダメみたいなエラーメッセージが出て止まってしまいます。
3月 13th, 2014 at 17:24
福助さん
/System/Library/Frameworks/Ruby.framework/Versions/1.8/usr/bin/ruby
にRuby 1.8が入っているので、そちらを使えば変換できます。
3月 14th, 2014 at 12:41
iMac 2012(Core i5 3.1GHz)上で、Mavericks Xcode 5.1/Auxiliary October2013でmakeしたところ、(boincを走らせていたため概算ですが)英辞郎+略辞郎が13時間、和英辞郎が17時間でした。Segmentation Faultは起こらずに済みました。
3月 14th, 2014 at 14:01
最近のMacは速くなりましたねえ。まあ、それでもこんなに時間がかかる(一般向けの)テキスト処理はそうそうないでしょうけど(笑)。
5月 4th, 2014 at 23:24
iMac 2012(Core i5 2.9GHz, メモリ8GB)上でcielavenierさんと同じ条件でmakeし、英辞郎+略辞郎のmake; make install;が9時間でした。英辞郎はv.140です。無事使えています。
Ruby 2.0.0が使えないかもしれないとのことだったので、先にRVMをインストールしてRuby 1.8.7をデフォルトにしてから実行しました。Ruby 2.0.0でできるかどうかは試していません。
蛇足ですが、terminal-notifierを導入してmake installと一緒に実行しておくと、終わったときに通知してくれます。システム環境設定で警告スタイルを「バナー」から「警告」にしておくとよいでしょう。
Tats_yさん、素敵なスクリプトを作っていただき本当にありがとうございました。こうやって長くメンテナンスされていくのがオープンソースの醍醐味ですね。
ところで、個人的には【レベル】【発音】…等の行が見出し語のすぐ下にあると嬉しいのですが、CSSだけではいじれないですよね。いずれスクリプトを解析して再度makeにチャレンジしてみようと思いますが、なにかヒントだけでもいただけたら嬉しいです。
5月 8th, 2014 at 09:44
>Mitsuさん
情報ありがとうございました。
>なにかヒントだけでもいただけたら嬉しいです。
「【レベル】」「【発音】」についても正規表現でマッチングさせて、配列に格納。後半の適当なところでprint文で出力……ということになると思います。けっこう面倒くさそうですが、頑張ってください。
5月 11th, 2014 at 22:57
Tats_yさん
ありがとうございます。データが大きいのでトライアンドエラーに時間がかかってしまうのが難点ですが、英辞郎のHPのサンプルデータを利用してできないかやってみます。
5月 11th, 2014 at 23:03
Tats_yさん
ありがとうございます。データが大きいのでトライアンドエラーに時間がかかってしまうのが難点ですが、英辞郎のHPのサンプルデータを利用してできないか挑戦してみます。
6月 9th, 2014 at 01:06
Tats_yさん
ご報告です.
英辞郎ver. 141,
Macbook Air(2012 Mid), OS X 10.8.5, Intel Core i7(2GHz), メモリ8GB
英辞郎+略辞郎のmakeは12時間弱で終了しました.
無事使用できています.ありがとうございました.
英辞郎の仕様かもしれませんが,ウェブ版と違って熟語表示がないのが辛いですね…
8月 8th, 2014 at 02:22
OSX 10.10では/System/Library/Frameworks/Ruby.framework/Versions/1.8が存在しない(∴Ruby 1.8が標準で付属しない)ようですので、可能でしたらツール群をRuby 2.0以降に対応させて頂けないでしょうか。
8月 21st, 2014 at 23:43
OSX 10.10です。
rvmを用いてRuby 1.8.7をインストールしました。
(参照:http://qiita.com/harry/items/180d87fc8259ceab3f95)
(参照:http://jasdeep.ca/2014/06/installing-ruby-1-9-3-mac-os-yosemite-rvm/)
Xcode6Betta5(command line tool入っています)、MBA(mid 2011) corei7 1.8GHz, 960GB SSD, 4Gb memory,英辞郎ver142です。
MyDictionary.xmlまで作れましたが、make出来ません。
Makefileの中身を
DICT_BUILD_TOOL_DIR = “Go/temp”
DICT_BUILD_TOOL_BIN = “$(DICT_BUILD_TOOL_DIR)/bin”
こちらのように変えました。
bin内のbuild_dict.shの書き換えはしておりません。
#!/bin/sh
#
#
#
#
DICT_BUILD_TOOL_BIN=$(cd “$(dirname “$0″)”; pwd)
この辺りを書き換える必要がありますか?
ここからどのようにしたら良いのか、手詰まりで分かりません。
terminal.appのシェルはデフォルトのログインシェル(bash)です。
ご教授頂けたら幸いです。宜しくお願いします。
下記は、xmlファイルの情報です。
GonoMacBookAir:project_templates Go$ make
“”“Go/temp”/bin”/build_dict.sh” “英辞郎” MyDictionary.xml MyDictionary.css MyInfo.plist
/bin/sh: -c: line 0: unexpected EOF while looking for matching `”‘
/bin/sh: -c: line 1: syntax error: unexpected end of file
make: *** [all] Error 2
GonoMacBookAir:project_templates Go$ ls -l
total 2697248
-rwxrwxrwx 1 Go staff 168919342 8 12 13:03 EIJI-142.TXT
-rw-r–r– 1 Go staff 172982058 8 21 19:36 Eijiro.txt
-rw-r–r–@ 1 Go staff 1234 8 21 22:52 Makefile
-rw-r–r–@ 1 Go staff 549 4 9 2011 MyDictionary.css
-rw-r–r– 1 Go staff 659111706 8 21 20:55 MyDictionary.xml
-rw-r–r– 1 Go staff 1052 11 26 2007 MyInfo.plist
drwxr-xr-x 5 Go staff 170 2 29 2012 OtherResources
-rwxrwxrwx 1 Go staff 120112639 8 12 13:13 REIJI142.TXT
-rwxrwxrwx 1 Go staff 3908888 8 12 13:03 RYAKU142.TXT
-rw-r–r– 1 Go staff 4062716 8 21 19:35 Ryaku.txt
-rwxrwxrwx 1 Go staff 251835352 8 12 13:17 WAEI-142.TXT
-rw-r–r– 1 Go staff 90 11 10 2007 cat.rb
-rw-r–r–@ 1 Go staff 6811 4 10 2011 eiji_conv.rb
drwxr-xr-x 4 Go staff 136 4 10 2011 extras
-rw-r–r–@ 1 Go staff 131 11 10 2007 ryaku_conv.rb
GonoMacBookAir:project_templates Go$ head -n 10 MyDictionary.xml
FFSP
略=<→Fossil Fired Steam Plant>●化石燃料蒸気プラント
utility industry
GonoMacBookAir:project_templates Go$ tail -n 10 MyDictionary.xml
bigboned
形<→big-boned>
organomercurial salt
有機水銀塩(ゆうき すいぎん えん)
8月 29th, 2014 at 09:30
自己解決しましたが、一応報告しておきます。
「project templates」と「bin」が「mkdir ~/temp」によりtempファイル内にある状態と仮定してください。
Makefileの中身を
DICT_BUILD_TOOL_DIR = “Users/Go/temp”
DICT_BUILD_TOOL_BIN = “$(DICT_BUILD_TOOL_DIR)/bin”
という風に変更しました。
ここで注意したのは「”」をMakefile内のものと微妙に変化する場合があります。
英辞郎→和英辞郎と変更する時も「”」の変化に注意が必要です。
binフォルダの中にある「build_dict.sh」は触っていません。
OS X 10.10だろうと、rubyを1.8.7にすれば順調に変更すれば、問題なく動作します。
Xcode6Betta5(command line tool入っています)、MBA(mid 2011) corei7 1.8GHz, 960GB SSD, 4Gb memory,英辞郎ver142
この環境で「英辞郎」のmakeに3時間、「和英辞郎」のmakeに7時間くらいかかりました。
「”」の形に注意です。
12月 16th, 2014 at 00:56
Ruby 1.8を使い続けるのは微妙なところなので、1.9以降に対応しました。
https://github.com/cielavenir/eiji_conv
ただし動作確認は最小限しか行っていません、ご注意を。
11月 1st, 2015 at 11:51
英辞郎のデータを辞書で扱えるようにする情報をありがとうございます。
iMac (27-inch, Mid 2011)Intel Core i7, 3.4 GHz, 16GB, OS X 10.11.1 (15B42)
でやってみました。
Xcodeは7.1,Dictionary Development Kitは2015-4-1のタイムスタンプ
の物でした。
そして、上記のRuby 1.9以降対応版、eiji_conv-masterのフォルダーの
ファイルを使いました。rubyのバージョンは、 2.0.0p645でした。
操作手順は、ちくりんさんを参考にしました。
http://tikurin2.blogspot.jp/2013/01/os-x.html
所要時間ははっきり分かりませんが、** Note: Long key text. Skipped lineが300行ほどでましたが、辞書の作成にたどりつくことができました。
ありがとうございました。ご報告まで。
11月 1st, 2015 at 14:07
報告ありがとうございます。
おー、みなさんの尽力で新しいバージョンのツールへの対応が進んでますね。本当、感謝です。
2月 14th, 2016 at 17:35
貴重な情報、ツールをありがとうございます。
El Capitanへのアップデートを機に英辞郎ver. 144.1テキストデータの組み込みを試みました。
MacBook Pro (13-inch, Mid 2012), 2.5 GHz Intel Core i5, 4 GB, OS X 10.11.3、
Xcode 7.2.1、Ruby 2.0.0、Ruby 1.9以降対応版eiji_conv-masterのファイルを使用しました。
本ブログや関連のページを参考にして、英辞郎の組み込みに成功しました。同様に和英辞郎+例辞郎の組み込みを試みたのですが、makeの段階でParse Failerで止まってしまいました。和英辞郎単独、例辞郎単独でも同じエラーが出ました。以前に同様のエラー(http://d.hatena.ne.jp/saka-san/20100313 )が報告されており、長い見出し語が原因で、eiji_conv008の使用で解決したとのこと。そこで、eiji_conv.rbをXcodeで開き、
「 next if temp_index.length > 512 #見出し語が長すぎる項目はスキップ」
の行の512の数値を小さくしたところ、make時のエラーを回避できました。作業時間がかかるので、いくつまで減らせばよいのか検討したわけではありませんが、私の場合は128にして成功しました。とりあえずご報告まで。
2月 14th, 2016 at 18:27
>Borodinskiiさん
ああ、それはご苦労様でした!
しかし、以前は問題なかったのに、不思議ですね。Appleの辞書変換ツールのアルゴリズムも時々変更されているのかもしれませんね。