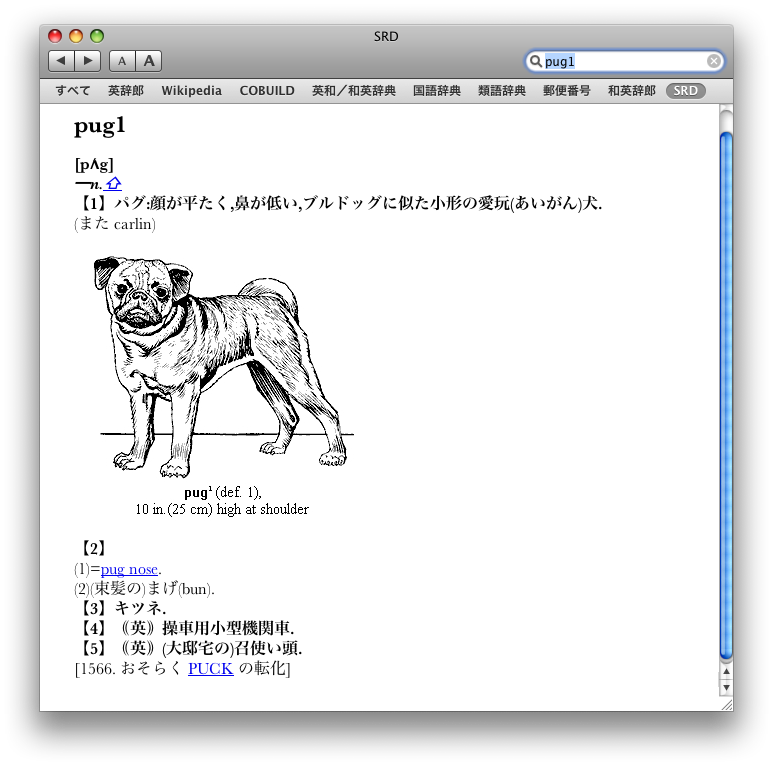
Leopardの「辞書」アプリで「ランダムハウス英語辞典」を使う
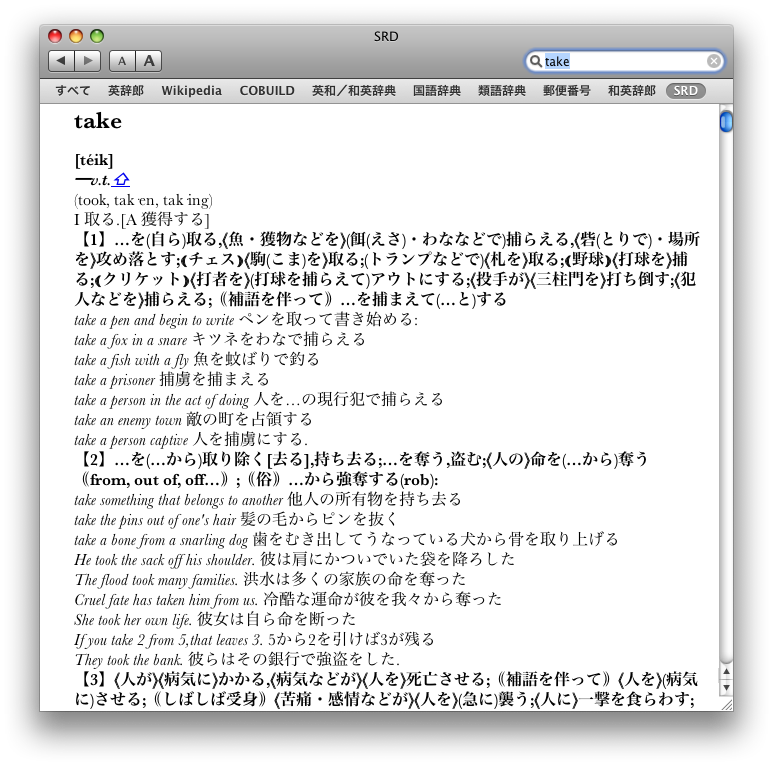
5月 11th, 2008 Leopardの辞書アプリ(Dictionary.app)で英辞郎を使えるようにしたおかげで、海外のサイトを読むのもずいぶん楽になった。しかし、単語の意味などをもう少し詳しく知りたいという時は、英辞郎だとちと物足りない。そこで、だいぶ前に買ったまま、ほとんど活用していなかったランダムハウス英語辞典(第二版)をDictionary.app用に変換してみることにする。
Leopardの辞書アプリ(Dictionary.app)で英辞郎を使えるようにしたおかげで、海外のサイトを読むのもずいぶん楽になった。しかし、単語の意味などをもう少し詳しく知りたいという時は、英辞郎だとちと物足りない。そこで、だいぶ前に買ったまま、ほとんど活用していなかったランダムハウス英語辞典(第二版)をDictionary.app用に変換してみることにする。
ランダムハウス英語辞典が使えるMac用の辞書ソフトとしては、すでにJammingがあるが、できればDictionary.appにまとめたいところ。検索機能はJammingが格段に優れているが、日常的にさっと調べるならDictionary.appの方が使いやすく感じる。まあ、変換処理自体が面白くなってきたというのもあるのだけど。
○Windows上で辞書データを吸い出す
ランダムハウス英語辞典のデータは独自形式になっていて、私ではとても手に負えない。そこで、太田純氏が作成されたランダムハウス英語辞典Toolkitを使わせていただいた。これは、ランダムハウス英語辞典のデータをHTMLに変換するWindows用のツール。当然、利用するにはWindows(Parallels Desktop for Macなどの仮想環境でもOK)が必要になる。ランダムハウス英語辞典Toolkitでは、srd2html.iniというファイルで設定を行うが、私は以下の内容にした。
BASEPATH = c:\srdtmp\
OUTPATH = c:\srd\
DICPATH = c:\Program Files\小学館\ランダムハウス英語辞典\
DATAPATH = c:\Program Files\小学館\ランダムハウス英語辞典\
SORTCMD = c:\Windows\System32\sort.exe
MACINTOSH = 0
FIGURE = 1
JPEG = 1
SOUND = 0
GENSOUND = 0
COMPLEX = 0
QUICKJUMP = 0
QJITEMS = 3
QJLINES = 30
QUICKRET = 1
ITALIC = 0
PRONSYM = SPEAKER
JUMPSYM = BIPOD
ARROWSYM = JUMP
RETSYM = RETURN
これで、srd2html.exeを実行すればsrd.htmlが生成される。また、figフォルダにはBMPの画像ファイルがコピーされるので、これを適当なツールでJPEG形式に変換しておく。
○生成されたHTMLを修正する
 私の手元にあるランダムハウス英語辞典は、どうもデータにバグがあるようで、そのままではエラーが出てしまう。そこで、適当なテキストエディタを使ってsrd.htmlを修正する。修正内容は以下の通り。
私の手元にあるランダムハウス英語辞典は、どうもデータにバグがあるようで、そのままではエラーが出てしまう。そこで、適当なテキストエディタを使ってsrd.htmlを修正する。修正内容は以下の通り。
・Avalementの項目の文字化け
Avalementの項目(ID=”1190300″)に文字化けがある。「屈曲によってスキーが」という文章に修正。
・adsuki beanの重複
adsuki beanという項目が重複している。ID=”224900″の方は文章量の少ない項目(ID=”239400″を参照している方)を残し、ID=”239400″の方は文章量の多い項目を残す。
・その他の重複項目
その他にもいくつかの重複項目がある。
IDを列挙すると、
353200, 393700, 1076900, 1077000, 1077100, 1121500, 1225000, 1396900, 1885200, 1904900, 1914600, 2088900, 2101900, 2106100, 2108500, 2365200, 2452600, 2536200, 2536600, 2717300, 3121300, 3167800, 3265100, 4445800, 5760300, 5861700, 5873700, 5959500, 6897700, 6907700, 7160400, 7193700, 7194400, 7286000, 7298600, 7625900, 7679100, 7696200, 7789200, 7792900, 8064000, 8211700, 8229600, 8257300, 8501900, 9015400, 9047000, 9051400, 9199600, 9318000, 9327700, 9336700, 9338000, 9338700, 9350700, 9351200, 9351400, 9370200, 9443000, 9466600, 9549300, 9553900, 9746700, 10118300, 10661800, 10781200, 11034200, 11085300, 11321500, 11414300, 11414400, 11582200, 11600800, 11608200, 11853900, 11854400, 11856600, 11858300, 11858400, 11858500, 11860000, 12068100, 12214700, 12216400, 12585600, 12596500, 12596600, 13562000, 14796100, 14821200, 15057600, 15098200, 15157400, 15163100, 15205800, 15243200, 15251400, 15288700, 15560100, 15654900, 15841300, 15841400, 15848500, 15877300, 15877400, 16102800, 16110300, 16125800, 16402500, 16403100, 16465100, 16465200, 16465300, 16465400, 16465500, 16465800, 16466000, 16466100, 16466400, 17115600, 17138800, 17231400, 17435800, 17543200, 17919100, 17928100, 17934200, 17936600, 17936700, 17936800, 17960800, 18293800, 18403900, 18432400, 18440900, 18795400, 19176600, 19441700, 19639100, 19763300, 19789700, 19807900, 19827700, 19852500, 19856600, 19879300, 19879700
……勘弁してください。どうも「kimono」とか「harakiri」など、日本語由来の単語に問題があるようだ。重複しているIDの項目を削除する(実は、同じIDでも内容が微妙に異なる。片方は説明が詳しく、片方は出典が書かれているという具合。気になる人は適宜編集してほしい)。
○Xcodeをインストールする
ここからはMac上での作業になる。
・英辞郎の場合と同じく、Mac OS X用の開発ツール「Xcode」をインストールする(Leopardのインストールディスクの「Optional Installs」→「Xcode Tools」→「XcodeTools.mpkg」を実行)
・「/Developer/Exmaples/Dictionary Development Kit/project_templates」フォルダを適当な場所にコピーする
○変換用のスクリプトを準備・実行
 ・ここから、変換用のスクリプトをダウンロードして、(コピーした)「project_templates」フォルダに解凍する(同じファイル名は上書き)
・ここから、変換用のスクリプトをダウンロードして、(コピーした)「project_templates」フォルダに解凍する(同じファイル名は上書き)
・生成したsrd.htmlも、同じく「project_templates」フォルダにコピーする
・画像の含まれる「fig」フォルダは、「project_templates」内の「OtherResources」フォルダにコピーする。
・「ユーティリティ」フォルダの「ターミナル」アプリケーション(Terminal.app)を起動して、「cd」コマンドで(コピーした)「project_templates」フォルダに移動する
・ターミナルで、「ruby srd_conv.rb < srd.html | ruby gaiji_rep.rb srd.lst | ruby ucs4_to_utf8.rb > MyDictionary.xml ; make ; make install」と入力。
・「辞書」アプリケーション(Dictionary.app)を立ち上げると、ランダムハウス英語辞典(SRD)が使えるようになっているはず。
○発音記号もコピー&ペーストできる
オリジナルのランダムハウス英語辞典では、発音記号などをすべて外字によって表現していた。そのため、説明文を別のアプリケーションにコピーしても、文字化けしてしまう(Jammingを使った場合でも同じ)。
Dictionary.app用に変換したデータでは、これらをUnicodeの文字で表示しているので、見たとおりの状態でコピー&ペーストできる。この変換テーブル(srd.lst)は、私が近い形を探して作ったので、間違いがあるかも。手書き文字のように、Unicodeではどうしても表現しきれなかったものもいくつかある。
○日本語のキーワードからも引ける
ランダムハウス英語辞典には、日本語の検索インデックスも用意されている。和英辞典ほどではないが、結構便利である。
○変換スクリプトの話
 ・srd_conv.rbは、srd.htmlをXML形式に変換。
・srd_conv.rbは、srd.htmlをXML形式に変換。
・gaiji_rep.rbは、外字をUnicodeの文字に変換。
・一部の文字が文字実体参照(&#x????という形式で文字を表現する)になっているので、これをucs4_to_utf8.rbで実際の文字に置き換えている。Unicodeのいわゆる文字コード(UCS-4)からUTF-8への変換方法は、『文字コード超研究』を参考にしている。この本は、文字コードの基本知識から具体的な変換方法まで、わかりやすく書かれていてオススメ。
5月 21st, 2011 at 16:46
こんにちは。思わずtweet入れてしまったのですが、面識もなく突然で申し訳ありません。
こちらの記事を拝見してランダムハウスの変換を試してみているのですが、ターミナルでrubyのコマンドを入力した後、
srd_conv.rb:39:in `iconv’: “\203\275L\201[\202\252\220??\202??”… (Iconv::IllegalSequence)
from srd_conv.rb:39
“””/Developer/Extras/Dictionary Development Kit”/bin”/build_dict.sh” “My Dictionary” MyDictionary.xml MyDictionary.css MyInfo.plist
– Building My Dictionary.dictionary.
– Cleaning objects directory.
– Preparing dictionary template.
– Preprocessing dictionary sources.
seek() on closed filehandle ARGV at /Developer/Extras/Dictionary Development Kit/bin/make_line.pl line 55, chunk 15235.
という表示が出たまま止まってしまいました。ただカーソルは点滅しています。
Xcodeは新しく出ているv4を使っていて、v3の時とproject_templatesフォルダへのパスなどが変わっていますがそれ以外は上記の解説の通り試してみています。
もしかして変換処理が進んでいないのでは?と思ったのですが。
このまま放って置いてもいいものかもわからないため、もしよろしければ何かヒントをいただけませんでしょうか?どうぞよろしくお願いいたします。
5月 21st, 2011 at 17:03
最初の”ruby srd_conv.rb < srd.html”ですでにエラーが起こっているみたいですね。
うーん、srd.htmlは正常に変換されていますかね? ちょっと下記を参考にしてみてください。
http://www.binword.com/blog/archives/000569.html#comment-3286
5月 23rd, 2011 at 10:32
こんにちは、ご返信どうもありがとうございました。
あの後辞書データをwindowsで取り出すところからやり直してみたのですが、この後もエラーが出たのでそのエラー内容に沿って、上記の記事内で挙げておられる重複している辞書データIDの主に出典が書かれてあるほうを削除してみた結果、無事辞書ファイルの生成がうまくいきました。
5月 23rd, 2011 at 10:38
無事に生成できたとのこと、何よりです!